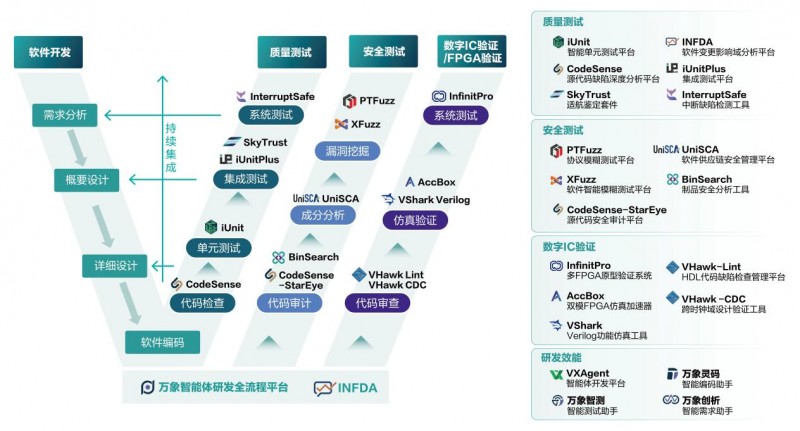
可伸缩微服务告警系统设计指南 基础软件服务视角

在分布式微服务架构中,告警系统是保障系统稳定性的核心组件。一个设计良好的可伸缩告警系统,能够实时感知服务异常,快速定位问题,并为运维团队提供清晰的决策依据。本文将从基础软件服务的角度,探讨如何设计一个面向微服务、具备高可伸缩性的告警系统。
一、 核心设计原则
- 去中心化与自治性:告警系统本身应作为一组微服务进行构建,避免单点故障。告警规则管理、事件收集、通知分发等功能模块应独立部署和扩展。
- 可伸缩性:系统必须能够应对服务实例数量激增、告警规则复杂化以及事件流量峰值的挑战。这要求数据采集、处理和存储各层都支持水平扩展。
- 实时性与低延迟:从指标异常被检测到告警信息送达负责人,延迟应控制在分钟级甚至秒级,以实现快速响应。
- 智能化与降噪:避免告警风暴。通过告警聚合、依赖关系分析、智能降噪(如基于机器学习识别误报)和静默策略,确保告警信息精准有效。
- 最终一致性:在分布式环境下,告警状态的同步允许短暂延迟,但需确保最终所有相关组件状态一致。
二、 系统架构分层设计
一个典型的可伸缩微服务告警系统可分为四层:
1. 数据采集层
职责:从各个微服务实例、容器、主机及中间件(如数据库、消息队列)中实时收集指标、日志和追踪数据。
关键技术:
* 采用代理(Agent)模式,在每个服务节点或边车容器(如Sidecar)中部署轻量级采集代理(如Prometheus Node Exporter, Telegraf)。
- 利用服务网格(如Istio)的遥测数据。
- 统一数据格式,推荐使用OpenTelemetry标准。
- 可伸缩设计:采集代理无状态,可随服务实例自动扩缩容。数据推送可采用轻量级队列(如Kafka)进行缓冲,解耦采集与处理。
2. 数据处理与存储层
职责:对采集的原始数据进行清洗、聚合、计算,并存储时间序列数据与告警事件。
关键技术:
* 流处理引擎:使用Flink、Spark Streaming等对数据进行实时流式处理,计算复杂指标和检测异常模式。
- 时序数据库:采用专为时序数据优化的数据库(如Prometheus TSDB, InfluxDB, TimescaleDB)存储指标,支持高效查询和压缩。
- 事件存储:使用Elasticsearch或Cassandra存储结构化的告警事件和上下文日志,便于检索和分析。
- 可伸缩设计:流处理作业和存储集群均可水平扩展。采用分片(Sharding)策略分散数据存储与计算压力。
3. 告警引擎层
职责:这是系统的“大脑”,负责根据预定义的规则(如阈值、频率、持续时间)或机器学习模型,对处理后的数据进行分析,判断是否触发告警。
关键技术:
* 规则管理:提供灵活的DSL或UI界面,支持多维度、多条件的告警规则定义(如:某服务的P99延迟 > 200ms 持续5分钟)。
- 告警判定:规则引擎(如Prometheus Alertmanager的规则模块)需高效、无状态,便于横向扩展。
- 告警聚合与路由:将相同根源的告警合并,并根据标签(如service=order-service, severity=critical)路由到不同的通知渠道和接收人。
- 可伸缩设计:告警引擎应设计为无状态服务,通过负载均衡器分发计算任务。规则和状态信息可持久化到外部存储(如Redis, ETCD)。
4. 通知与协作层
职责:将触发的告警信息通过多种渠道(如钉钉、企业微信、Slack、短信、电话)发送给相关人员或系统,并集成到运维协作平台(如Jira, PagerDuty)。
关键技术:
* 多渠道通知器:支持插件化扩展各种通知渠道。
- 告警生命周期管理:跟踪告警从触发、确认、处理到解决的完整流程,支持认领、备注、升级等操作。
- 可视化仪表盘:集成Grafana等工具,提供实时监控视图和历史告警分析。
- 可伸缩设计:通知发送器应异步化,使用消息队列(如RabbitMQ, Kafka)解耦,防止因某个渠道阻塞影响整体系统。
三、 关键可伸缩性策略
- 事件驱动架构:各层之间通过消息队列(如Kafka)进行异步通信。这不仅能缓冲流量峰值,还能实现组件间的解耦,便于独立扩展和容错。
- 无状态服务设计:数据处理、告警引擎等核心服务应设计为无状态的,使其可以轻松地通过增加或减少Pod/容器实例来应对负载变化。状态信息(如规则、会话)交由外部存储管理。
- 分片与分区:对数据(如按服务名、租户ID)和计算任务进行分片,使工作负载能均匀分布到多个处理节点上。
- 弹性伸缩:在Kubernetes等容器编排平台上,基于CPU/内存使用率、消息队列积压长度等指标,配置Horizontal Pod Autoscaler(HPA),实现自动扩缩容。
- 多租户与资源隔离:为不同业务线或团队提供逻辑或物理隔离的命名空间、队列和计算资源,避免相互干扰。
四、 基础软件服务集成考量
作为基础服务,告警系统需与微服务生态无缝集成:
- 服务发现:自动从服务注册中心(如Consul, Nacos, K8s Service)发现新服务实例并开始监控。
- 配置中心:告警规则应支持从配置中心(如Apollo, Nacos)动态加载和更新,无需重启服务。
- 统一认证与授权:集成公司的统一身份认证系统,控制不同团队对告警规则和数据的访问权限。
- 与CI/CD流水线集成:在部署新版本时,可自动关联相关服务的监控仪表盘和告警规则,实现可观测性即代码(Observability as Code)。
,设计一个面向微服务的可伸缩告警系统,需要从架构上贯彻解耦、无状态和事件驱动原则,并在数据采集、处理、判定和通知各层采用可水平扩展的技术组件。深度集成到基础软件服务体系之中,使其成为运维智能化的坚实基石,从而在复杂的分布式环境下,保障业务的持续稳定运行。
如若转载,请注明出处:http://www.meichengditu.com/product/33.html
更新时间:2026-06-19 04:17:16